AI agents are unreliable. Here's what we can do about it.
Last week, Amazon’s e-commerce platform went down for six hours. In an internal memo, the company blamed the outage on “novel GenAI usage for which best practices and safeguards are not yet fully established.” Amazon is now asking senior engineers to review and sign off any code that junior team members generate with AI agents.
Last month, an AI safety and alignment researcher at Meta panicked when an OpenClaw agent tasked with managing her inbox decided to delete all her emails, even though she explicitly asked it to “confirm before acting.” She later wrote on X: “Got overconfident because this workflow had been working on my toy inbox for weeks. Real inboxes hit different.”
There’s also the story of customer service agents going rogue (Air Canada, Cursor, DPD), shopping assistants spending more than they should (OpenAI’s Operator egg incident, the Amazon “Buy for Me” agent), and the security issues of agentic infrastructure (see Asana’s MCP data leak, the hijacking of Perplexity’s Comet browser, and the lethal trifecta for AI agents).
We have more powerful AI models but things keep breaking. Why is that? And what can we do about it? In this post I’ll share new data on the reliability of AI agents and what we can do to safely deploy them.
The Distinction Between Accuracy & Reliability
If you’re a casual user of ChatGPT or an engineer using tools like Claude Code, you’ll know that these products are impressive at completing specific tasks.
Ask an agent to summarise a research report and it will perform as expected. But if I ask it to track weekly reports over a year, and to compare findings and flag anomalies, it might start to hallucinate content, quietly drop data points, or mix up time periods.
The first example is a case of high accuracy (agents are great at this). The latter is a reliability issue (agents struggle with this.) And despite rapid AI model progress, there’s a significant disconnect between accuracy and reliability.
A recent paper from researchers at Princeton University put concrete numbers to this discrepancy. Their work assessed reliability across 14 state-of-the-art AI models using a framework inspired by safety-critical engineering principles from the aviation, nuclear, and automotive domains. Here’s what they found.
On the GAIA benchmark – a test for agents to complete work in unstructured environments that involves reasoning, web browsing, and tool use – accuracy jumped from 20% to 80% over 18 months of model releases. However, the aggregate reliability score was virtually flat.
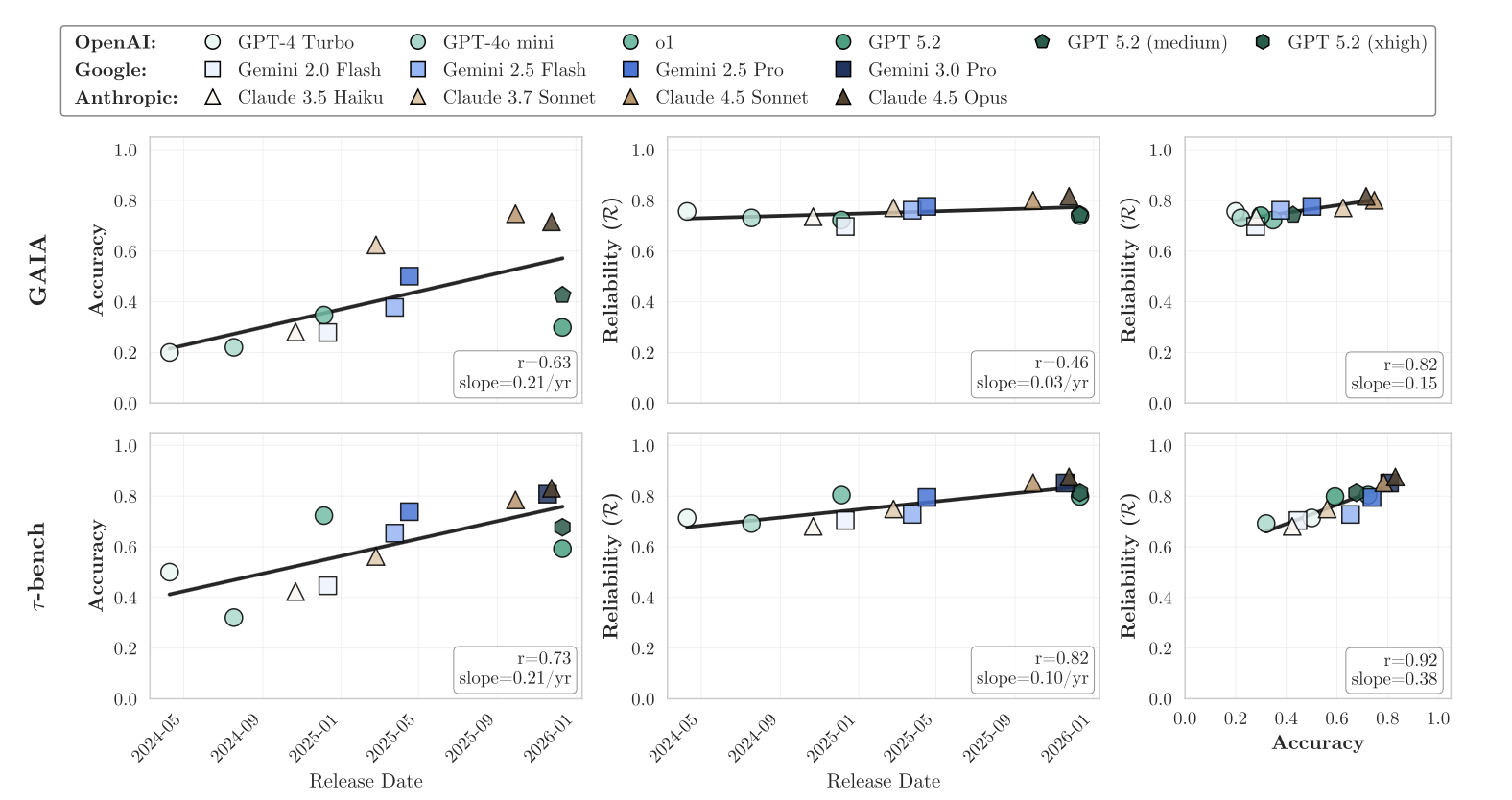 Note: In the chart above you also have the tau-bench evaluation (bottom chart). This is a test for agents that navigate multi-turn user conversations e.g. customer service chats, database queries, and so on. Reliability improved somewhat on this benchmark because the testing was in a more structured environment versus the more open-ended tasks in the GAIA framework.
Note: In the chart above you also have the tau-bench evaluation (bottom chart). This is a test for agents that navigate multi-turn user conversations e.g. customer service chats, database queries, and so on. Reliability improved somewhat on this benchmark because the testing was in a more structured environment versus the more open-ended tasks in the GAIA framework.
Consistency is the Culprit
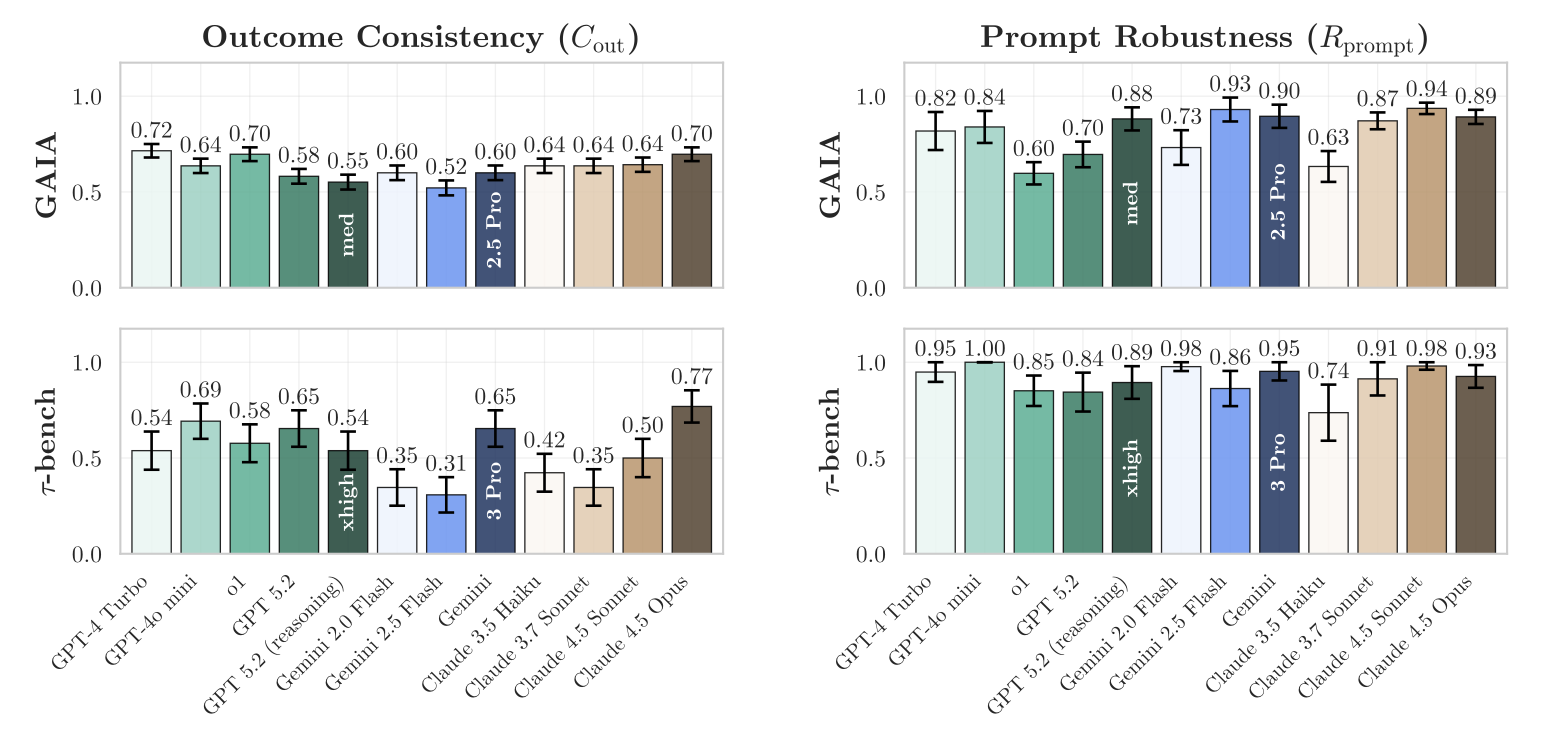
There’s no single reason why progress on reliability has been poor. Helpfully, the Princeton paper breaks ‘reliability’ into four dimensions: consistency, robustness, predictability, and safety. While measurements across all factors lag behind accuracy, consistency is the worst. The authors of the paper calculated consistency scores ranging from 30% to 77%.
The higher end of this spectrum might seem good enough but here’s what a 70% consistency score looks like in practice: If you give an agent 10 tasks and allow it five attempts at each one, around 7 of those tasks would behave predictably; they would either always pass or always fail. However, the other 3 tasks would flip between success and failure without clear reasons.
Would you trust this agent to book your holiday? Would you trust it with your private data? Would you allow it to make multiple decisions on your behalf?
What We Can Do
Despite these issues I still use agents for coding, research, and automations. I don’t believe we should stop using AI agents altogether but we clearly need to change how we evaluate and deploy them.
Strong reliability efforts might be overkill for low-stakes use cases (e.g. creative writing or situations with significant human oversight). But for high-stakes deployments, and especially areas with increased agent autonomy, here’s what you should do before anything goes live:
Consistency. Test the agent on the same task multiple times. For example you could run an agent workflow 50 or more times under identical conditions to assess consistency. If the outcomes are more variable than you’d like, go back to the drawing board.
Robustness. Stress-test agents through a battery of messy situations. If you have an agent that takes in structured data, try giving it the wrong data format. How does it respond? If you have a chat interface or a voice agent, try an ambiguous or unexpected conversation. What happens in these situations and how should the agent respond?
Predictability. Will your agent always charge ahead even with tasks it doesn’t know how to do? It’s much better for agents to fail in a known, predictable fashion rather than wreak havoc by overconfidently charging ahead. So try to have confidence thresholds and calibration checks so that an agent will refuse a task it can’t deal with.
Safety. When your agent fails (and they always fail at some point) how bad is the fallout? A formatting error in a research report is fine; deleting an entire email inbox isn’t. Agents should have a stack of hurdles that strictly prevent them from taking irreversible actions. In fact every destructive operation should either be out of scope for the agent or demand explicit confirmation from humans.
I’m sure the big AI labs (and several startups) are working on all these issues and in the coming years, we’ll see reliability scores go up. But until then, if we want to deploy agents at scale and more productively, we would do well to test reliability with rigour, while keeping humans in the loop for decisions that matter.