GLM 5.2 vs Opus 4.8: Cheaper and Almost as Good
A new open-source AI model is getting a lot of attention on X, and having now used it myself, I believe the excitement is justified.
Enter GLM 5.2, an open-weight, frontier AI model from the Chinese AI lab Z.ai, released under a permissive MIT License for broad commercial and non-commercial use. To get a feel for its capabilities, I gave it the same coding task as Anthropic’s Opus 4.8 (one of the most expensive proprietary models on the market). GLM’s output was almost just as good but over 80% cheaper.
The reason people are raving about GLM 5.2 is its performance. For example on this web development benchmark, it comes second, right behind Anthropic’s state-of-the-art model, Fable.
I’ve long believed that cheaper and more accessible AI is going to be a big part of the future, but it’s only after using GLM 5.2 that I’ve felt this strongly about it. Open models will inevitably become common in tech stacks. Just as any developer reaches for PostgreSQL for databases or React for frontend work, reaching for an open source model will soon be just as routine. The cost advantage has always been a benefit with open-source AI. But what’s clearer now is that cutting-edge performance is here too, so much so that it would be silly to write off open models as the inferior option.
Just how good is GLM 5.2? Benchmarks aside, I ran my own test with a simple ask. I kept it intentionally small for good reason. Sure, it would have been more fun to ask for a 3D game or some fancy database-driven workflow app, but big outputs are hard to judge fairly, both on correctness and on taste.
So I went with a cap table instead. A cap (or capitalisation) table is a financial model that shows who owns what percentage of a company and how those slices shrink when a new investor joins the share register. I asked each AI model to create an interactive version of this document so that founders could explore how raising money for their company impacts their position.
You can read the full prompt I used here. This task is a good test because unlike a flashy demo, it’s quick to build, easy to get subtly wrong, but fast to verify.
In terms of tech stack the project had two agentic coding harnesses and AI model pairs: Claude Code with Opus 4.8, and OpenCode with GLM 5.2 (both routed through OpenRouter). Each AI model ran without any other human input, including a step the AI could test its work in a browser. Here’s what each AI model came up with.
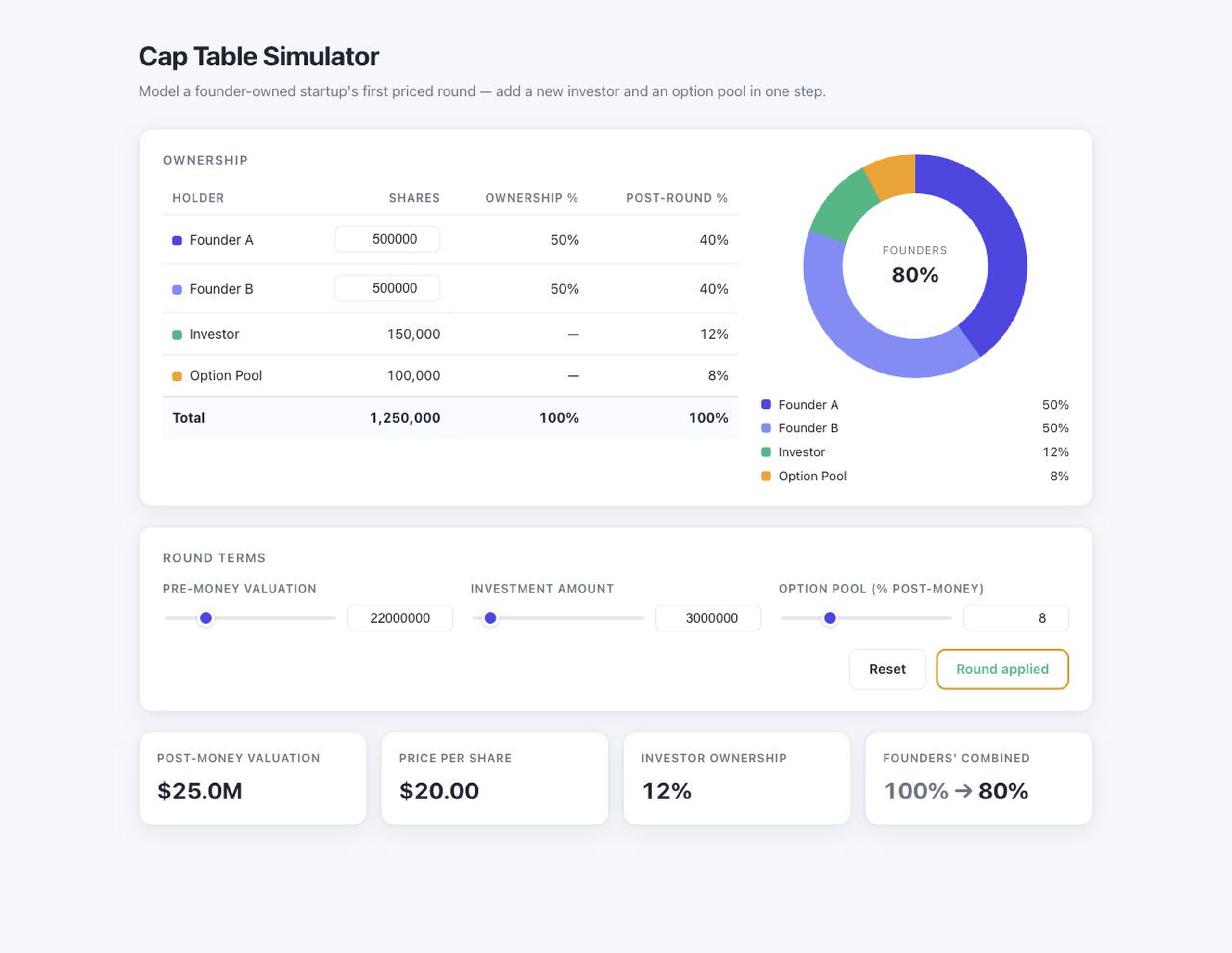
GLM 5.2 + OpenCode
Opus 4.8 + Claude Code
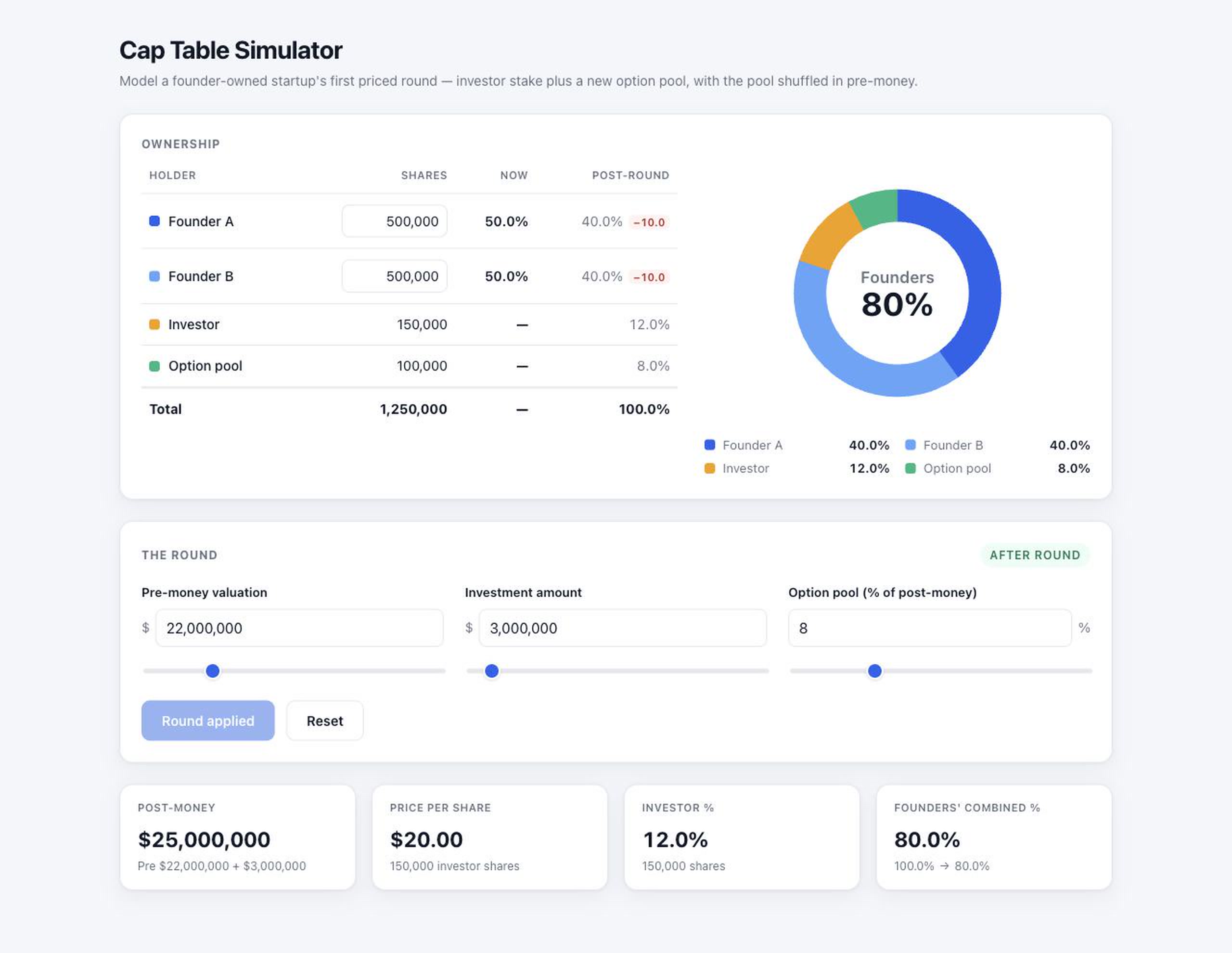
You can try the live versions here: GLM version and Opus version. Both came from a single prompt, with no follow-up.
The TLDR assessment? Both Opus and GLM are great and I’d happily start with either. Opus was a little more polished. However, GLM was very close, and not just that. It was 7.5 times cheaper than Opus 4.8 ($0.31 vs. $2.33, or about 87% less), and it completed the task in roughly the same time (roughly 5.5 minutes each.) GLM also used fewer tokens.
Given the two options, I’d take GLM and the massive cost saving.
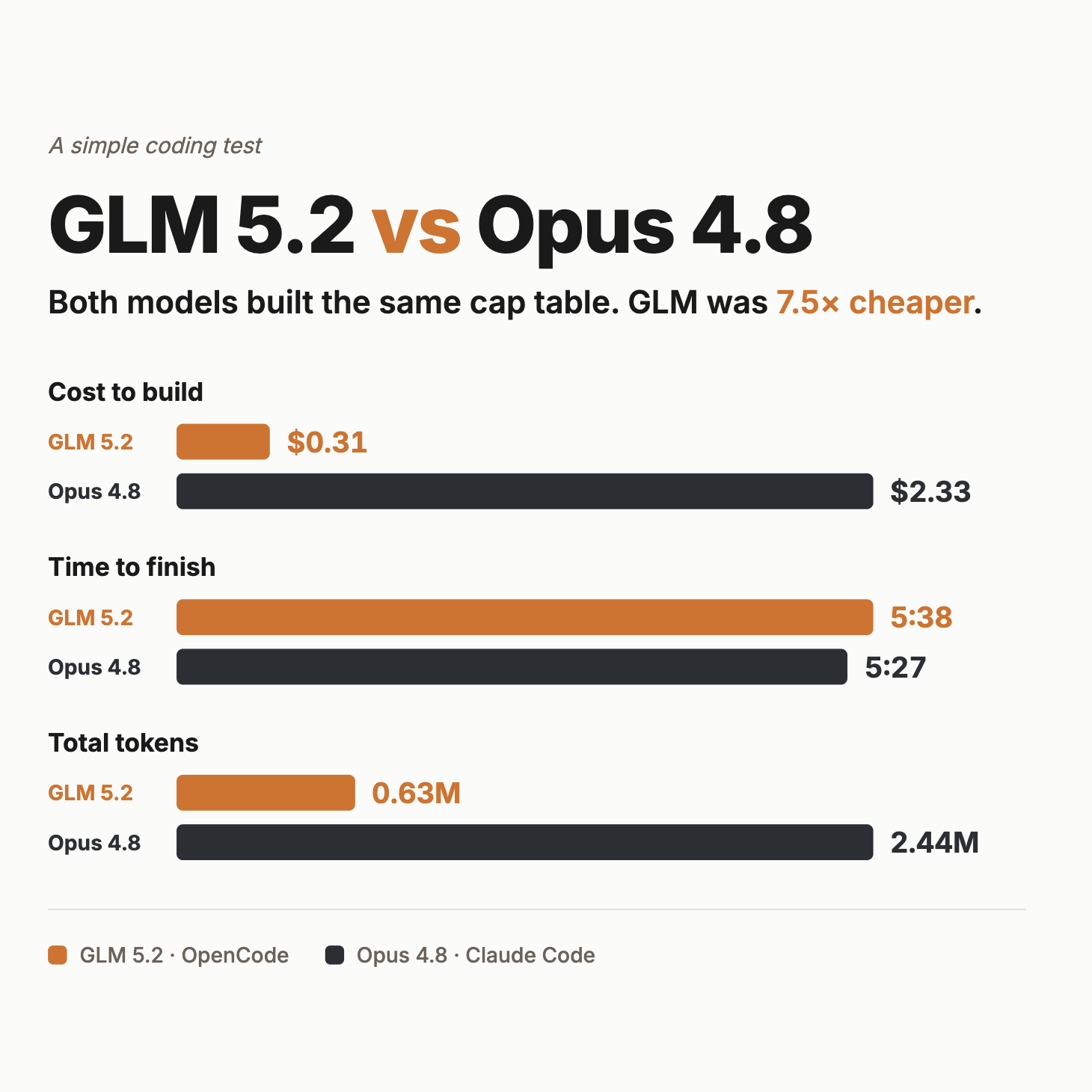
Some quirks are worth noting though. GLM’s first draft was buggy. Founder rows were hidden on load, the share total didn’t update after applying an investment round, and there were a few other minor issues. But because the run included a browser-testing step, GLM used the Playwright MCP to open the page, saw the problems, and rectified each one. Opus had a browser-testing tool too, but its first draft was bug-free.
Overall Opus was slightly nicer. It showed a clear before-and-after state for the round and used stylistic badges to highlight the change in founder ownership after an investment, alongside clear formatting (e.g. currency symbols and thousand separators). GLM looks good, too, but its table labels were more ambiguous, its inputs were bare numbers, and it didn’t hold up as well on mobile.
Both apps were not production-ready in one shot either. Each produced strange results at the edges. If you enter a deal that doesn’t mathematically work — say an investment so large, plus an option pool so big, that together they would give away more than 100% of the company — neither app stops you. GLM responded with an absurd cap table running into the trillions of shares, and Opus showed the investor owning 98% while reporting zero shares for everyone.
That said, these flaws are quick to fix with a follow-up prompt. I used GPT-5.5 in Codex for the engineering and Claude Code with Opus for design changes to get a better version of the app. It’s available here.
As a text-only model, GLM is a fantastic option for coding and other agentic tasks where visuals are not a priority. You can also pair it with multimodal AI models if design is important. Still, going forrward I expect to use GLM (or other open-source alternatives) whenever I hit those frustrating limits on my personal Claude and OpenAI plans.
In a few years, when the hardware of personal computers improves, we’ll all be running a meaningful part of generative AI work with models like GLM locally. This is fantastic for privacy, speed, and cost. I can’t wait to see what that enables for the application layer of AI.